Voicify AI
Visit- Introduction:
Create custom AI voices and transform text into audio instantly.
- Added on:
Oct 27 2024
- Company:
Voicify AI Ltd
- Voice Synthesis
- Audio Editing
- Text-to-Speech
AI Audio
Custom Voices
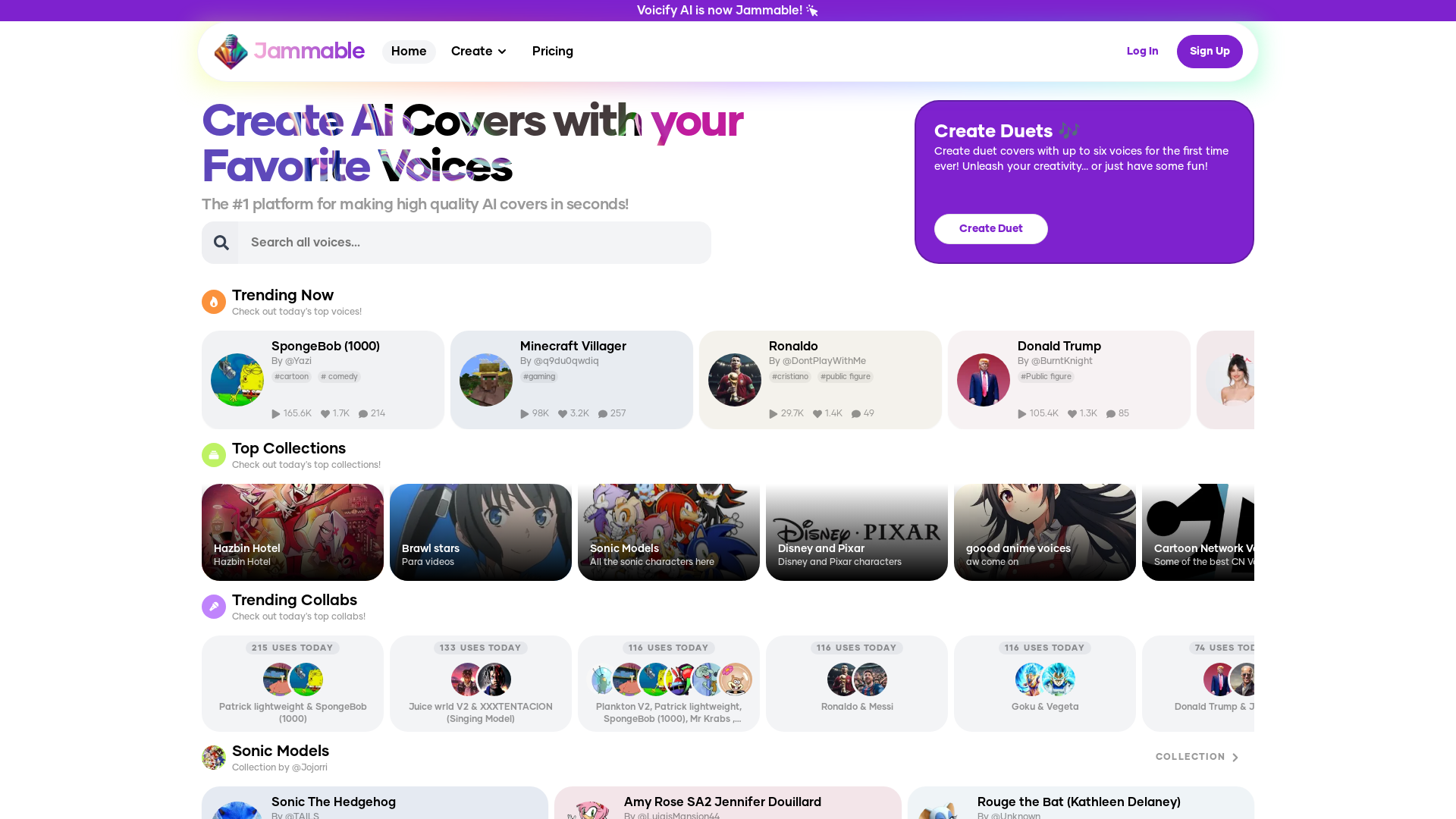
Introducing Jammable: The AI-Powered Voice Synthesis Platform
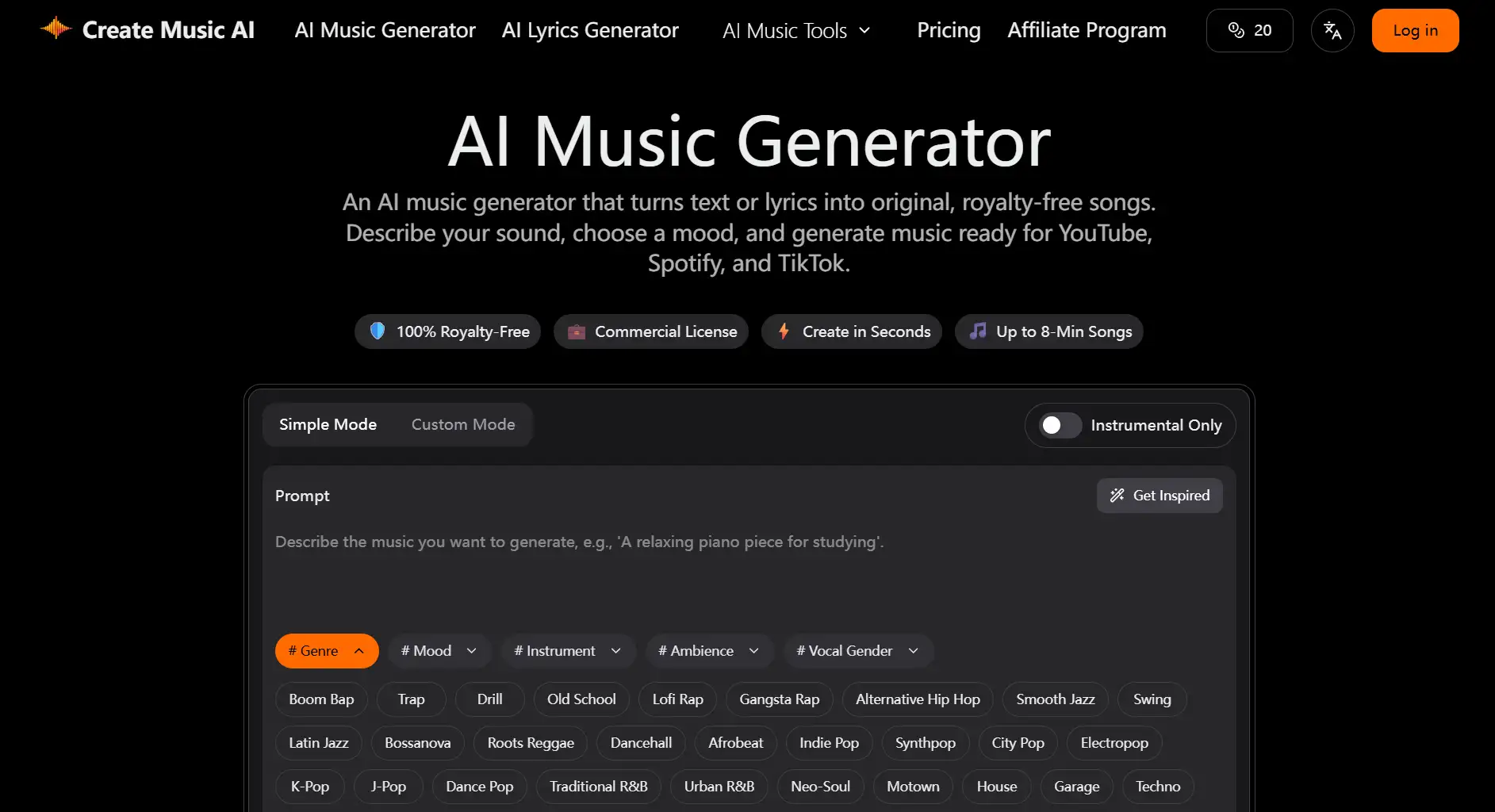
Jammable is a cutting-edge AI platform designed to simplify voice creation and audio editing for users of all skill levels. Leveraging advanced machine learning, Jammable allows users to generate custom voice models, convert text to realistic audio, and remove unwanted noise, providing high-quality, versatile audio solutions. Whether for personal projects, creative work, or professional use, Jammable's intuitive platform offers a blend of precision and ease to elevate audio experiences.
Primary Functions of Jammable
Custom Voice Model Creation
Example
A user creates a synthetic voice for a fictional character.
Scenario
Ideal for content creators and developers, Jammable lets users design unique voices to add personality and realism to digital characters, enhancing audience engagement.
Text-to-Speech Conversion
Example
A writer converts text articles to audio files.
Scenario
Perfect for bloggers or news sites, Jammable enables users to turn written content into spoken audio, making information accessible to a wider audience.
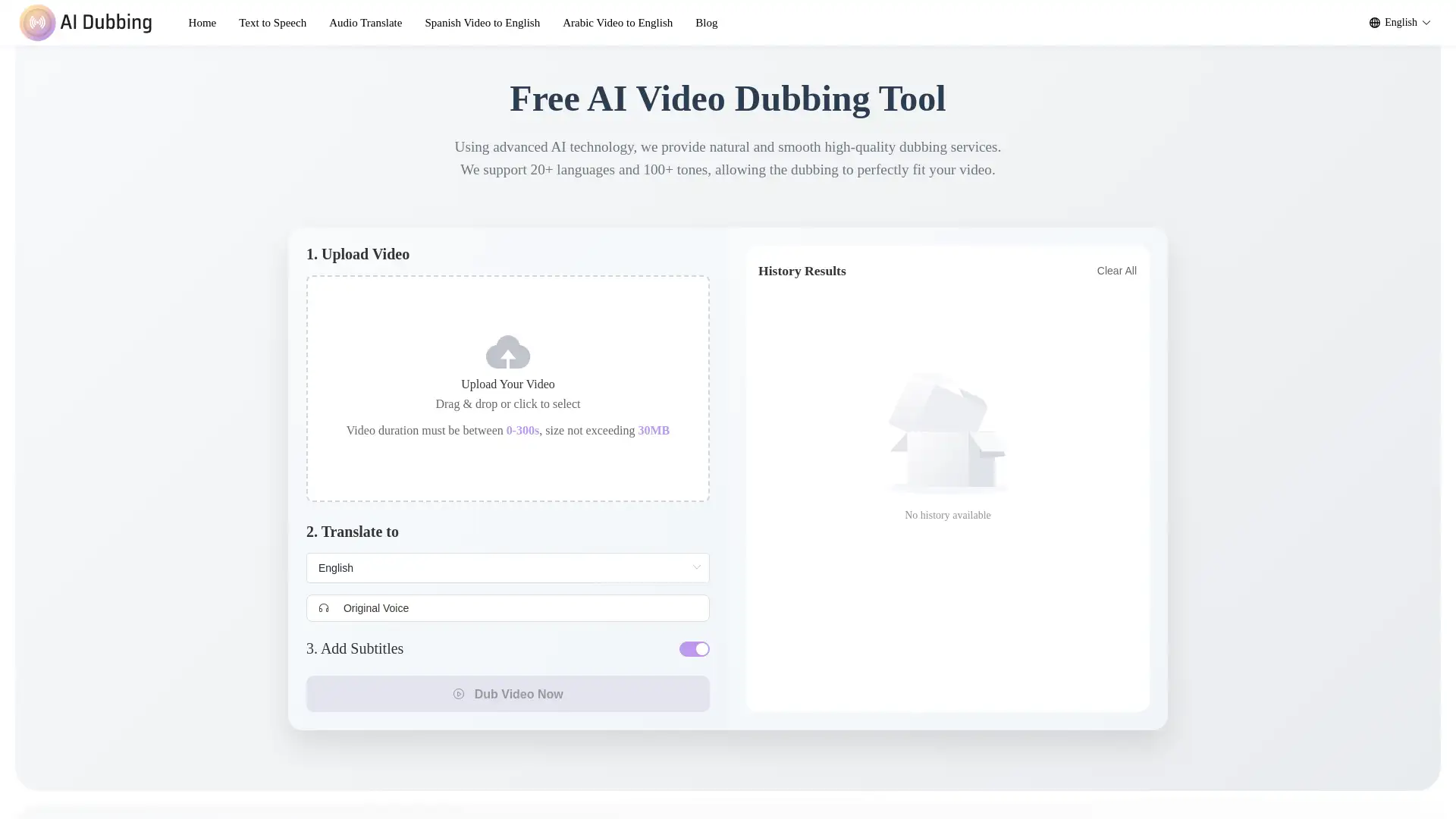
Audio Editing Tools
Example
A podcaster removes background noise from a recording.
Scenario
With Jammable's noise reduction and audio clean-up tools, podcasters and video creators can polish their audio to professional standards, ensuring high-quality sound.
Who Can Benefit from Jammable?
Content Creators
Podcasters, YouTubers, and streamers can use Jammable to create distinctive voiceovers, improve audio quality, and expand their content’s reach through accessible text-to-speech formats.
Developers and Game Designers
Game and app developers can leverage Jammable’s custom voice models to bring unique characters to life, providing engaging experiences for users and enhancing storytelling.
Educational Content Providers
Teachers and e-learning professionals can transform text materials into engaging audio resources, making learning more interactive and accessible for students.
Visit Over Time
- Monthly Visits1,502,768
- Avg.Visit Duration00:03:42
- Page per Visit5.37
- Bounce Rate42.52%
Geography
- United States37.39%
- Vietnam11.88%
- Germany5.15%
- Australia3.38%
- United Kingdom3.24%
Traffic Sources
How to Get Started with Jammable
- 1
Sign Up and Create an Account
Begin by registering on Jammable's platform to access its tools and features.
- 2
Explore or Create Voice Models
Choose from existing voice models or create a custom one to suit your project needs.
- 3
Generate and Edit Audio
Use Jammable’s conversion and editing tools to create high-quality audio, which you can download or share as needed.
Related Youtube Video About Voicify AI

How to Use Speechify's AI Voice Studio for Beginners (Best AI Text to Speech)

Free Text to Speech AI: Clone your voice and make it sing!

Best FREE AI Text To Video Generator | Better Then Invideo AI and Pictory Ai

FREE AI Voice Generators | Text to Speech | 2024

How to Create Voiceovers Using AI Voices with Fliki

Change Your Voice to ANY CELEBRITY with This Free AI

Text to Video in Any Language | Invideo AI Tutorial

How to Make an AI Singing Voice in 2024
Common Questions
Voicify AI Pricing
For the latest pricing, please visit this link:https://www.jammable.com/pricing
Basic
$5/month or $50/year
Access to basic voice models
Limited text-to-speech conversions
Standard audio editing tools
Pro
$15/month or $150/year
Access to premium voice models
Unlimited text-to-speech conversions
Advanced audio editing tools
Enterprise
Custom pricing
Dedicated support and custom voice models
API access for large-scale use
Customizable tools and premium features